
Webサイト内の情報を自動的に取得する技術をスクレイピングといいます。
とある所用でVBAを使ってつくってほしいと依頼されたものの、対象のサイトではIEが未対応(VBAではIEを使ってスクレイピングをかけます)でうまく取得できませんでした。
Webサイトの運営者ならご存じだと思いますが、今やIEは機能的に乏しくコーディングする時も「ブラウザがIEなら……」と例外処理をするほど。
つまりVBAでスクレイピングのマクロをつくっても将来的に使えなくなる可能性が高そうです。まぁEdgeに移行するでしょうけども。
そこで前々から気になっていたGAS(Google Apps Script)を使ってスクレイピングをしてみることにしました。ついにGASデビューです。
プログラムの内容
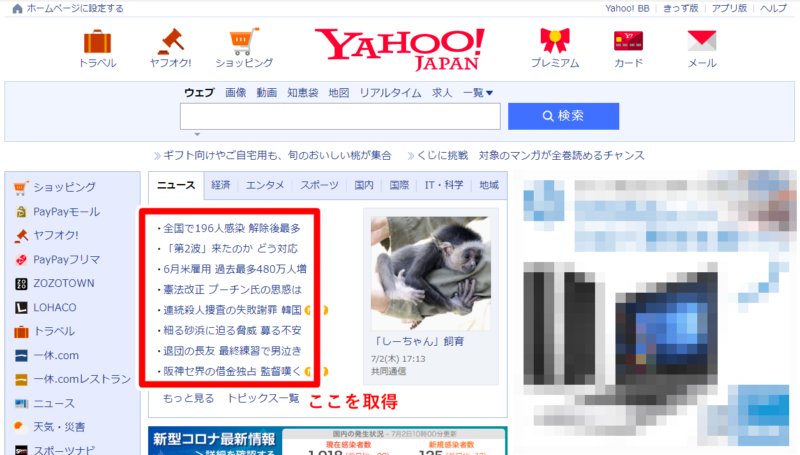
例として、Yahoo! Japanのトップページにあるニュースのヘッドラインのタイトルを取得しましょう。
8つ分ニュースがあるので、繰り返し処理を行います。
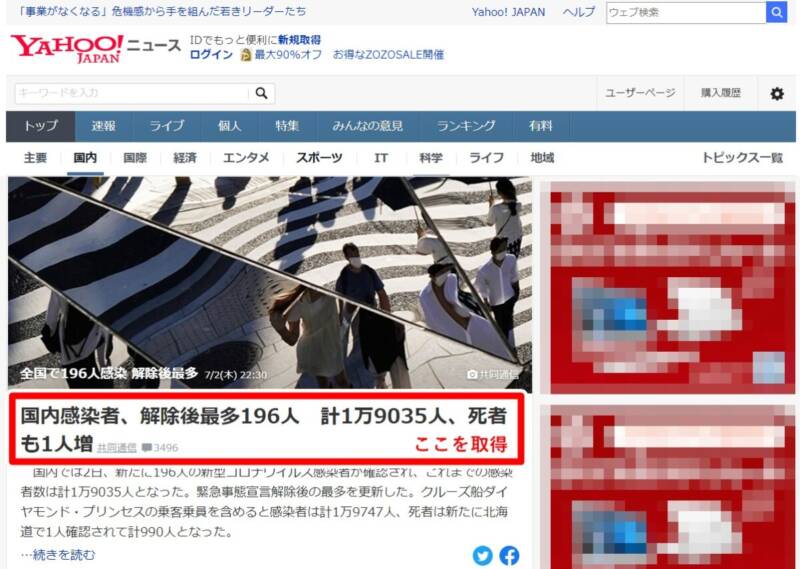
さらに各リンク先にアクセスして、そのページ内の見出しを取得します。
プログラミング
ドキュメントで取得したHTMLを確認する
対象となるHTMLを確認するには、ブラウザのデベロッパーツールを使用すれば可能ですが、スクリプトで取得した内容も含むためGASで取得できる内容と同じとは限りません。
GAS上で確認するにはログを表示させればいいのですが、こちらは字数制限があるためHTMLの場合ほとんど非表示になります。
そういうわけで、Google ドキュメント上に取得したソースを吐き出させます。
function myFunction() {
var url = 'https://www.yahoo.co,jp';
var src = UrlFetchApp.fetch(url).getContentText();
var document = DocumentApp.getActiveDocument();
document.getBody().setText(src);
}アクティブなドキュメントに出力します。
ただし、あまりにサイズが大きいと一度に保存ができずエラーが返ってきます。その場合は素直にソースを見た方がいいかも。
function myFunction() {
var url = 'https://www.yahoo.co.jp/';
var src = UrlFetchApp.fetch(url).getContentText('UTF-8');
const sheet = SpreadsheetApp.getActiveSheet();
var titleRegexp = new RegExp(/<div class="TRuzXRRZHRqbqgLUCCco9"><h1 class="_3cl937Zpn1ce8mDKd5kp7u"><span class="fQMqQTGJTbIMxjQwZA2zk _3tGRl6x9iIWRiFTkKl3kcR">.*?<\/span>/g);
var ankerRegexp = new RegExp(/text"><a class="yMWCYupQNdgppL-NV6sMi _3sAlKGsIBCxTUbNi86oSjt" href=".*?" data-ylk/g);
var title2Regexp = new RegExp(/<p class="pickupMain_articleTitle">.*?<\/p>/g);
var title;
var url2;
var src2;
var title2;
for (var i=0; i<8; i++) {
title = src.match(titleRegexp)[i].replace(/<div class="TRuzXRRZHRqbqgLUCCco9"><h1 class="_3cl937Zpn1ce8mDKd5kp7u"><span class="fQMqQTGJTbIMxjQwZA2zk _3tGRl6x9iIWRiFTkKl3kcR">/, '').replace(/<\/span>/, '');
sheet.getRange(i+1, 1).setValue(title);
url2 = src.match(ankerRegexp)[i].replace(/text"><a class="yMWCYupQNdgppL-NV6sMi _3sAlKGsIBCxTUbNi86oSjt" href="/, '').replace(/" data-ylk/, '');
src2 = UrlFetchApp.fetch(url2).getContentText('UTF-8');
title2 = src2.match(title2Regexp)[0].replace(/<p class="pickupMain_articleTitle">/, '').replace(/<\/p>/, '');
sheet.getRange(i+1, 2).setValue(title2);
}
}- UrlFetchApp.fetch(ソースを取得するURL):引数で指定されたページにアクセスしてソースを取得
- SpreadsheetApp.getActiveSheet():アクティブなGoogle スプレッドシートを取得
- new RegExp(/●●●.*?▲▲▲/g):正規表現。●●●と▲▲▲に囲まれた範囲を取得
- .*?は不特定数の文字列、gフラグはマッチしたすべてを返す
- /で囲む。/を含む文字列の場合は/の前に\(バックスラッシュ)を付ける
- .match(指定文字列)[i]:指定した文字列にマッチした範囲を取得。iは何番目かを表す(0スタート)
- replace(置換する文字列, 置換後の文字列)

結果はこうなりました。
豆知識ですが、Yahoo! Japanのトップページのヘッドラインは、13文字以内に収めて意味が伝わるように工夫されています。
パッと見て認識できるのがだいたいこの文字数だからとか、あるいはただ単にレイアウトの都合上この文字数に収めるようにしているとかなんとか。
Phantom JSを使ってスクリプト込みのページを取得
ソースのほとんどがスクリプトによって生成される場合、Phantom JSというヘッドレスブラウザを使用します。
このPhantom JSはサポートが終了しているため、将来性を考えないといけませんが、とりあえずプログラムを動かすということで。

無料だと1日あたり500回まで読み込みが可能です。大量のページを取得するのであれば回数を気にした方がいいですね。こちらは実際のサイトではなくサンプル化させたコードです。
とある所用でつくっていたコードをサンプル化しました。
function myFunction() {
var URL = 'https://www.sample.com';
var key = '取得したキーを入力';
var payload =
{url:URL,
renderType:'HTML',
outputAsJson:true};
payload = JSON.stringify(payload);
payload = encodeURIComponent(payload);
var url = 'https://phantomjscloud.com/api/browser/v2/'+ key +'/?request=' + payload;
var data = UrlFetchApp.fetch(url);
var json = JSON.parse(data.getContentText());
var src = json["content"]["data"];
var titleRegexp = new RegExp(/【startHoge01】([\s\S]*?)【endHoge01】/g);
var URL2Regexp = new RegExp(/【startHoge02】([\s\S]*?)【endHoge02】/g);
var subtitleRegexp = new RegExp(/【startHoge03】([\s\S]*?)【endHoge03】/g);
var title;
var URL2;
var subtitle;
var url2;
var data2;
var json2;
var src2;
const sheet = SpreadsheetApp.getActiveSheet();
var arr = src.match(titleRegexp);
for (var i=0; i<arr.length; i++) {
title = src.match(titleRegexp)[i].replace(/【startHoge01】/g, '').replace(/【endHoge01】/, '');
URL2 = src.match(URL2Regexp)[i].replace(/【startHoge02】/g, '').replace(/【endHoge02/】, '');
sheet.getRange(i+2, 1).setValue(title);
sheet.getRange(i+2, 2).setValue(URL2);
payload =
{url:URL2,
renderType:'HTML',
outputAsJson:true};
payload = JSON.stringify(payload);
payload = encodeURIComponent(payload);
url2 = 'https://phantomjscloud.com/api/browser/v2/'+ key +'/?request=' + payload;
data2 = UrlFetchApp.fetch(url2);
json2 = JSON.parse(data2.getContentText());
src2 = json2["content"]["data"];
subtitle = src2.match(subtitleRegexp)[0].replace(/startHoge03, '').replace(/endHoge03/g,'');
sheet.getRange(i+2, 3).setValue(subtitle);
}
}流れとしてはトップページのリンク先の一覧からタイトルとURLを取得し、そのURLを使って再度取得しページ内の情報をスクレイピングするというものです。
RegExpは配列としてデータを格納するので、lengthで最大数を取得できます。これを使ってループをかけています。Yahoo!の方でもこれ使えばよかったですね。
とりあえずこんなところで。他に良いやり方があればここに追記します。
ぶっちゃけスクレイピングはPythonのオハコらしいので、Pythonを勉強した方がよかったのかもですが。


コメント